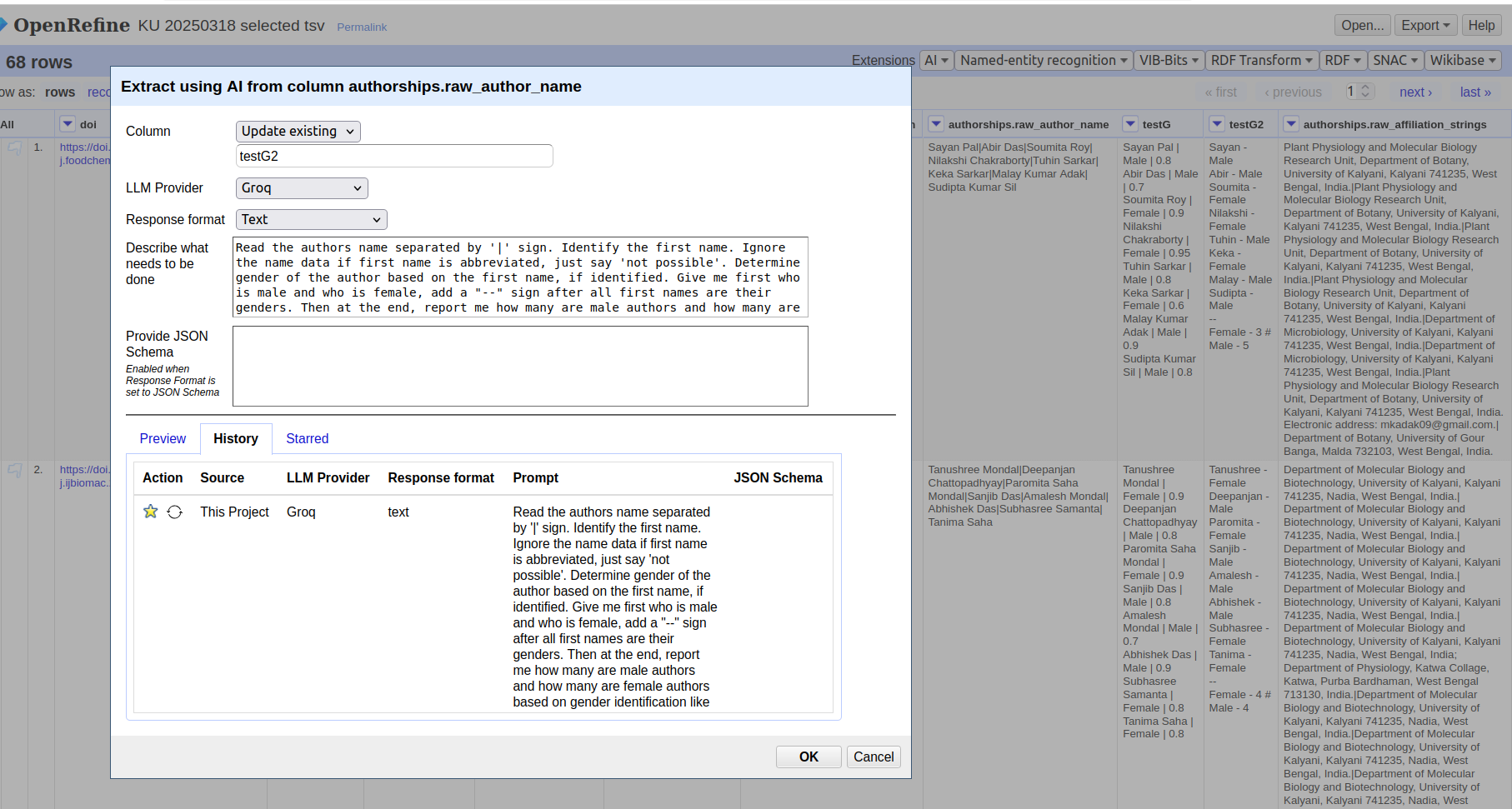
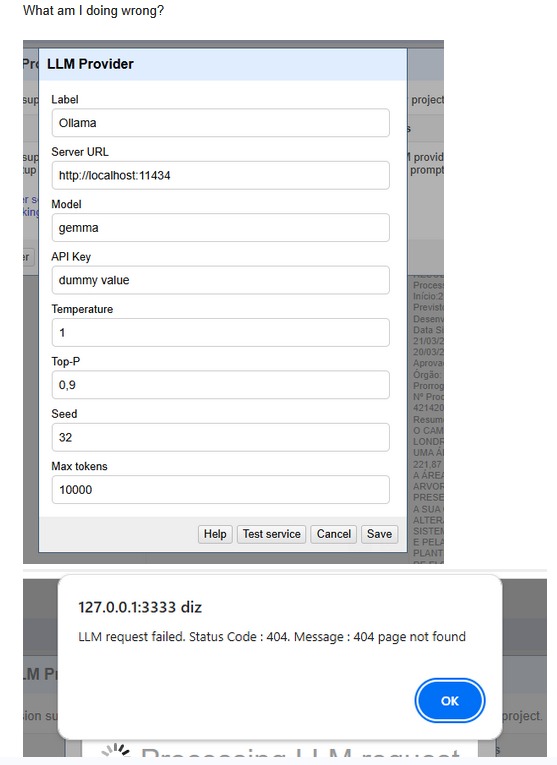
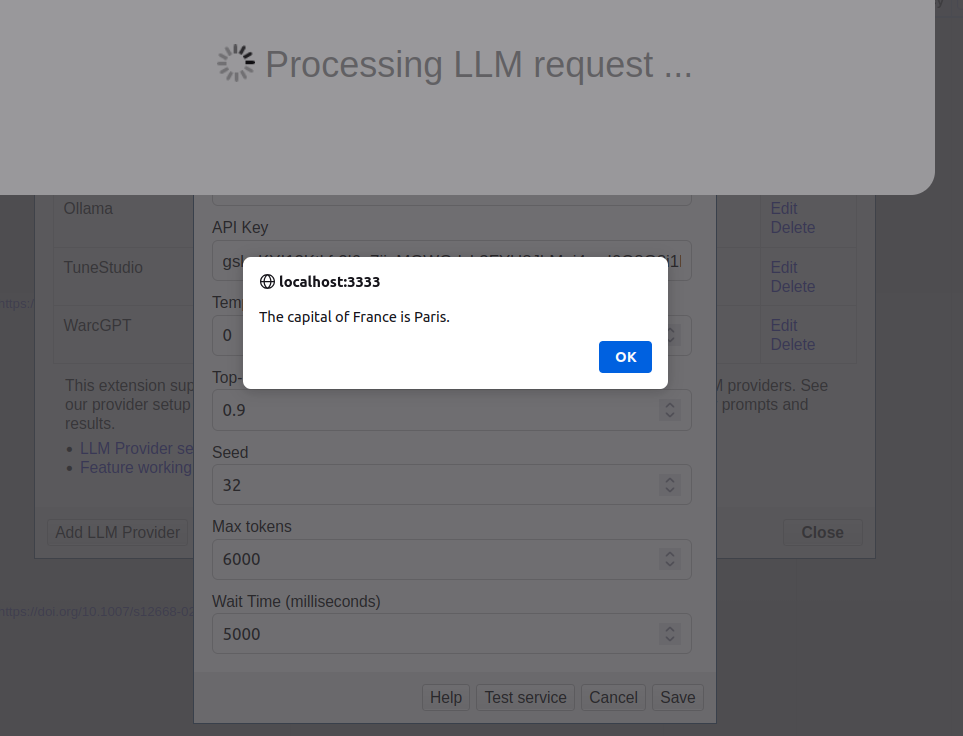
One more option will be helpful I think - Throttle delay (in milliseconds) - as those who are using free tier APIs (like me ) has often a rate limit. Such an option may improve our situation.
Thank you @psm. Glad this makes the extension more useful. Your input on support for supporting delay between requests makes sense, can you add this request here
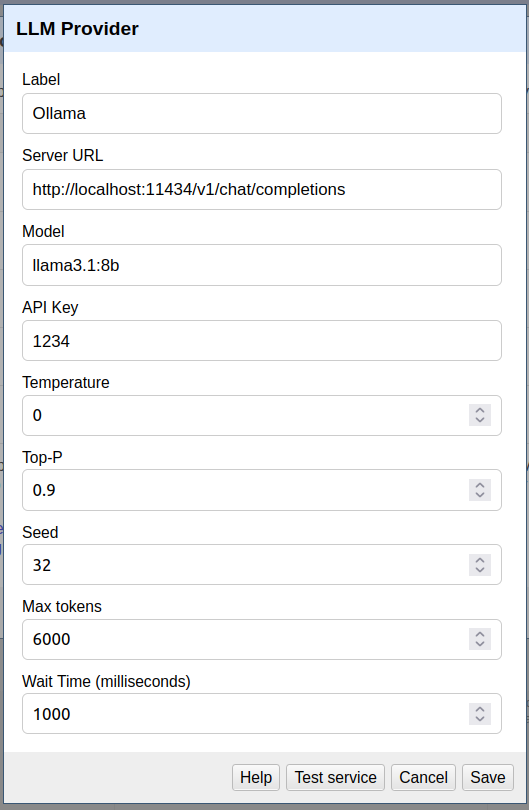
[in place of the model llama3.1:8b use your own model - ollama list command will provide the model names that you are using. Use the exact name under the Name column]
As someone quite familiar with OR and conventional data wrangling, but not in Python I also want to thank you for this very exciting lesson, which finally got me to take a closer look at Python. With deepseek-r1-distill-llama-8b I've achieved good results for my purpose in the first tests (I tried different LLMs but my challenges were not model related in the end).
Learnings:
Update your Mac to Sequoia …
If the prompt in the script contains an Umlaut (english language prompt), a utf-8 decoding error is thrown (only in OR/Jython). Took me a few hours, I just wanted to help out with austrian month names...
Removing the processes from the output seems easier (for me) in OpenRefine via GREL than doing it in Python
Hi @colognella, thanks for the feedback! Have you also tried the great LLM Extension by @Sunil_Natraj? It makes life much easier when dealing with local (but also remote) models.